Imagine a master chef who learns to cook by studying thousands of recipes, then starts creating entirely new dishes by combining and evolving those recipes. But here’s the twist—the new recipes they create become so good that other chefs start learning from these creations. This is called synthetic creations and it is exactly what’s happening in the AI world today.
The artificial intelligence landscape is experiencing a fundamental shift that’s reshaping how we think about data and machine learning. One of the most impactful trends emerging in 2025 is the use of synthetic data to train large language models (LLMs). This revolutionary approach where models can iteratively generate and learn from their own outputs, is transforming AI development from a data-hungry process dependent on massive real-world datasets to a more efficient and scalable methodology.
What is Synthetic Data and Why Does It Matter?
Synthetic data is artificially generated data used to augment real-world data, helping reduce the time, expense and legal hurdles of collecting and labeling large datasets. Synthetic data generation using LLMs involves using an LLM to create artificial data, which often are datasets that can be used to train, fine-tune, and even evaluate LLMs themselves.
The quality of an LLM is directly tied up with the quality of training data. Take DeepSeek for example, an open source frontier model developed for an incredibly low cost, which incorporated synthetic data for training. This breakthrough demonstrates that synthetic data isn’t just a supplementary tool—it’s becoming a primary driver of AI advancement.
The Self-Improving Loop: How LLMs Train Themselves
Perhaps the most fascinating development in synthetic data generation is the emergence of self-improving systems. This self-improving loop — where LLMs train and refine themselves using AI-generated data — is laying the groundwork for more scalable, efficient, and self-directed AI systems, marking a major shift in how models are developed and deployed.
As shown in research, LLMs-driven synthetic data generation enables the automation of the entire model training and evaluation process. Instead of waiting for human-labeled datasets, models now operate in dynamic training cycles where quality data is produced on the go.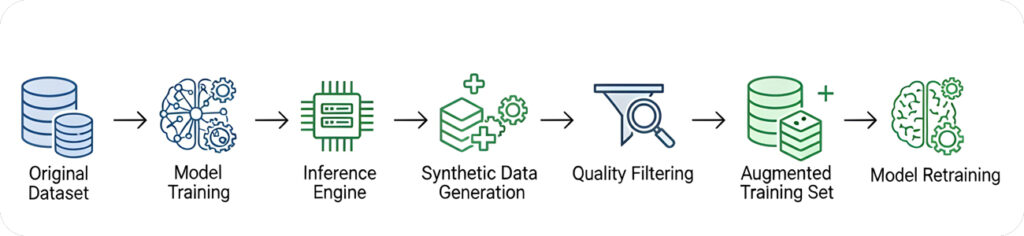
Real-World Examples of Success
DeepSeek’s Breakthrough: DeepSeek has demonstrated how this approach leverages data produced by other LLMs to create expansive, diverse, and task-specific training datasets, reducing dependence on costly or sensitive real-world data while enabling faster reasoning and more autonomous learning.
IBM’s LAB Method: IBM Research has developed Large-scale Alignment for chatBots (LAB), a systematic approach for generating task-specific synthetic data and assimilating new knowledge into foundation models without overwriting existing learning. IBM Research generated a synthetic dataset of 1.2 million instructions with the LAB method and found that their aligned models were competitive with state-of-the-art chatbots on various benchmarks, outperforming models trained on significantly larger data. In some cases, these LAB-tuned models even surpassed Microsoft’s Orca-2 chatbot.
NVIDIA’s Nemotron-4 340B: NVIDIA recently introduced Nemotron-4 340B, which is a set of open models designed for generating synthetic data. The Instruct model generates diverse synthetic data that mimics real-world scenarios, while the Reward model evaluates outputs based on factors like helpfulness and coherence.
Key Benefits of Synthetic Data Generation
1. Unparalleled Scalability
Synthetic data provides unparalleled scalability, allowing developers and researchers to generate large datasets rapidly for comprehensive model training without delays. With models like GPT-4, it’s now possible to synthetically produce datasets more comprehensive and diverse than human-labeled ones, at a fraction of the time.
2. Cost-Effectiveness
Generating synthetic data is often cheaper than sourcing, cleaning and labeling real-world data. It frees up resources for fine-tuning, deployment, & research and avoids the high costs of manual annotation.
3. Privacy Compliance
Synthetic data doesn’t include personal or sensitive information, making it easier to comply with the data privacy laws. In the financial sector, synthetic data is used to train LLMs for fraud detection and risk assessment, allowing simulation of rare market conditions without exposing sensitive financial information.
4. Bias Reduction
Synthetic data can be designed to balance datasets. This helps reduce biases present in real-world data and leads to fairer, more inclusive models. This approach is particularly valuable in industries with stringent privacy regulations, allowing organizations to maintain compliance while still leveraging data-intensive AI solutions.
Methods and Techniques
Distillation Approach
One of the most effective ways to generate synthetic data is known as distillation, where a larger, more advanced “teacher” model (such as Llama 405B) creates training examples for a smaller “student” model. This distillation process makes high-quality learning more efficient, especially in resource-constrained environments.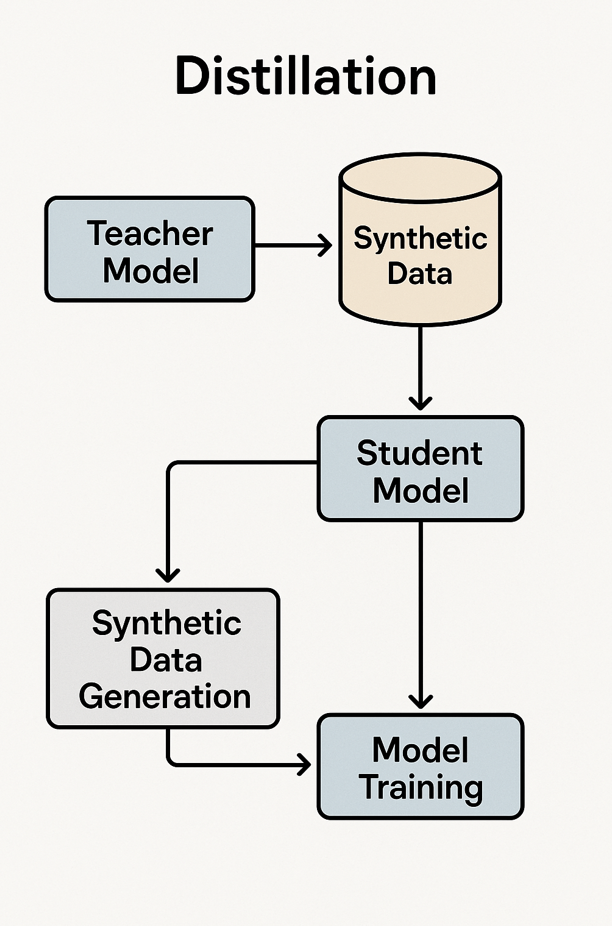
Model-in-the-Loop Systems
During training, a model like LLM-as-a-judge continuously evaluates the data and provides feedback. This helps adjust the data generation process in real-time, ensuring the data remains relevant and effective for training. This approach integrates a feedback loop where models are involved in generating and validating synthetic data.
Quality Control and Filtering
Filtering occurs at two critical stages of synthetic data generation: initially during context generation, and subsequently during the generation of synthetic inputs from these contexts. Employing LLMs as judges is a robust method for identifying and eliminating low-quality contexts.
The Future of Self-Training AI
Today’s artificial intelligence (AI) breakthroughs are being powered by synthetic data—a transformative approach to training and refining language models that’s faster, cheaper and more scalable than traditional methods.
Microsoft’s Evol-Instruct and Red Hat’s InstructLab (developed with IBM Research) offer automated, cost-effective ways to expand instruction-tuning capabilities. InstructLab, in particular, provides a scalable solution for enhancing LLMs without increasing the cost of development.
Looking ahead, LLMs-driven synthetic data generation may pave the way for developing next-generation LLMs, with insights emphasizing that data quality is crucial for effective model learning, while LLMs empower us to actively “design” what the models learn through data manipulation.
Conclusion – The Rise of Self-Sustaining AI
The synthetic data revolution isn’t just a technical shift, it is a fundamental reimagining of how the AI learns. As LLMs become increasingly capable of training themselves through synthetic data generation, we’re witnessing the emergence of truly self-improving AI systems.
At companies like SuperAnnotate, integrating synthetic data with human-generated data and model-in-the-loop approaches provides the best of both worlds: broad coverage, strong quality control, and higher cost efficiency.
The future of AI development will likely be characterized by these self-sustaining loops where models continuously improve through carefully generated synthetic data, making advanced AI capabilities more accessible, affordable, and aligned with human values and privacy requirements.